Introduction
Version: 1.0.0
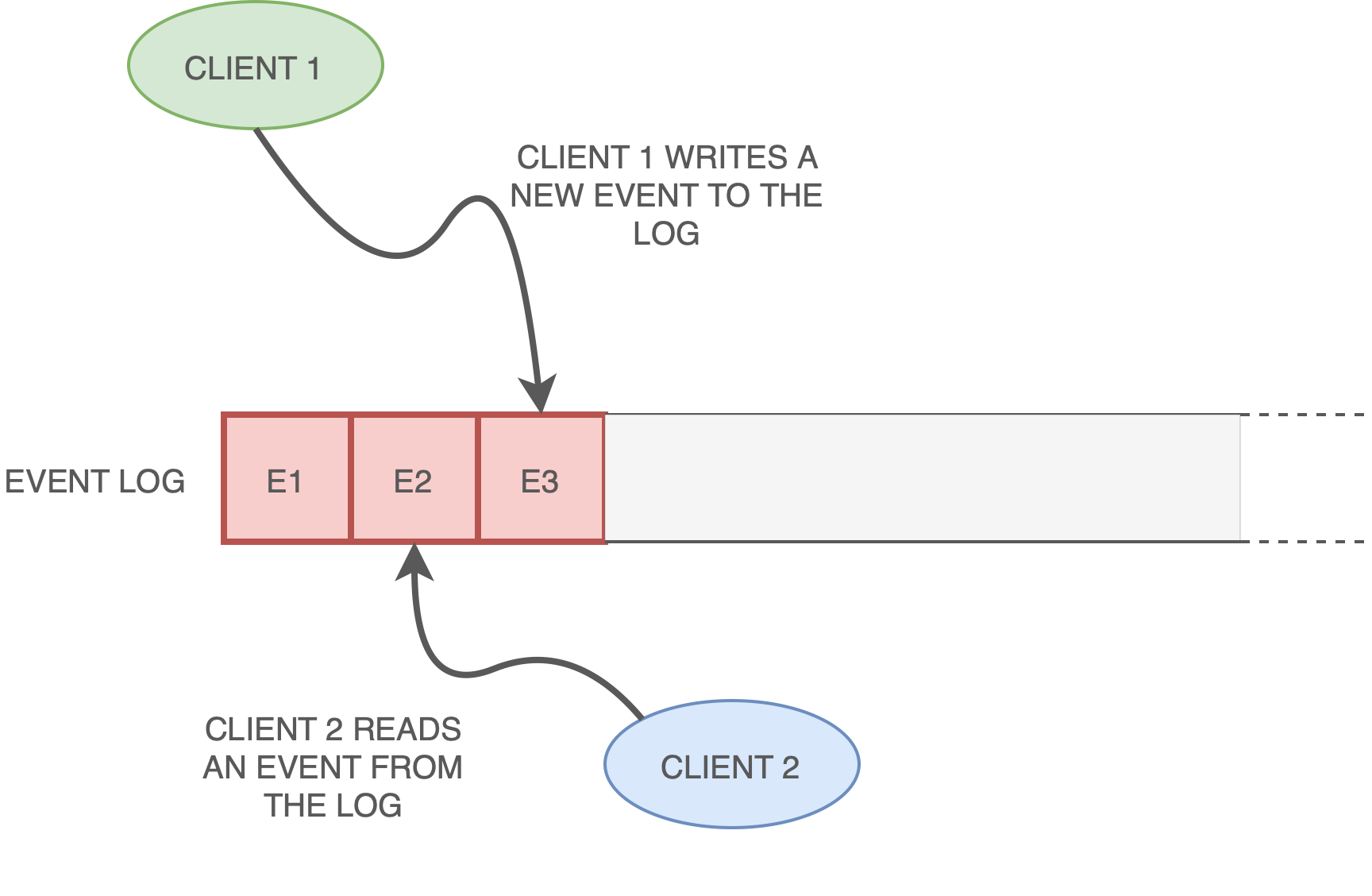
Apache Kafka® is an open-source framework that allows the reading, storing, and processing of data streams. It is designed to be deployed on distributed systems to allow high availability and scalability. The data exchanged in Kafka are events. Kafka Clients can read, process, and store events on a common distributed event log, which is kept aligned and synchronized by the Kafka Broker itself.
The Apache Kafka® Cloud Connector is a Kafka Client that allows interacting with a Kafka Broker by producing or consuming event streams via a publisher/subscriber model. The event stream is maintained in the broker and clients can publish, subscribe to, and process events. A good introduction to the fundamental Kafka concepts can be found at the Kafka Introduction.
Prerequisites
- The Apache Kafka® Cloud Connector installed on the system.
- A running Kafka Broker with well-known topics.
- If running ESF < 7.2.0, an
org.eclipse.kura.cloud.CloudServiceneeds to be instantiated in order to use Kura Protobuf payload encoding (see Endpoint Configuration).
General concepts
The provided cloud endpoint encapsulates a KafkaConsumer and a KafkaProducer.
Producers are those client applications that publish (write) events to Kafka, and Consumers are those that subscribe to (read and process) these events. In Kafka, producers and consumers are fully decoupled and agnostic of each other, which is a key design element to achieving the high scalability that Kafka is known for.
The Cloud Connection encapsulates an instance of a KafkaConsumer and an instance of a KafkaProducer. In order to have multiple producer or consumer instances you need to create multiple cloud connections. CloudPublisher or CloudSubscriber instances created using this Cloud Connector use the KafkaProducer or KafkaConsumer of the created Cloud Connection instance.
Kafka Topics
A topic in Kafka is a log of events. Logs are easy to understand, because they are simple data structures with well-known semantics. Topics have the following characteristics:
- Append only: new messages are always written at the end of the log.
- Topics can only be read by seeking an arbitrary offset in the log, then by scanning sequential log entries.
- Events in the log are immutable.
Topics are defined server-side, in a default setting they cannot be created dynamically by a Kafka Producer but they must be created in advance.
Kafka Partitions
A Kafka topic can be divided into one or more partitions, and the number of partitions per topic is configurable. Partitioning takes the single topic log and breaks it into multiple logs, each of which can live on a separate node in the Kafka cluster. This way, the work of storing messages, writing new messages, and processing existing messages can be split among many nodes in the cluster. Out of that, one partition will be the leader. All read and write to a topic goes through the leader, and the leader coordinates updating the replicas. If a leader fails, a replica in the list is assigned as the new leader.
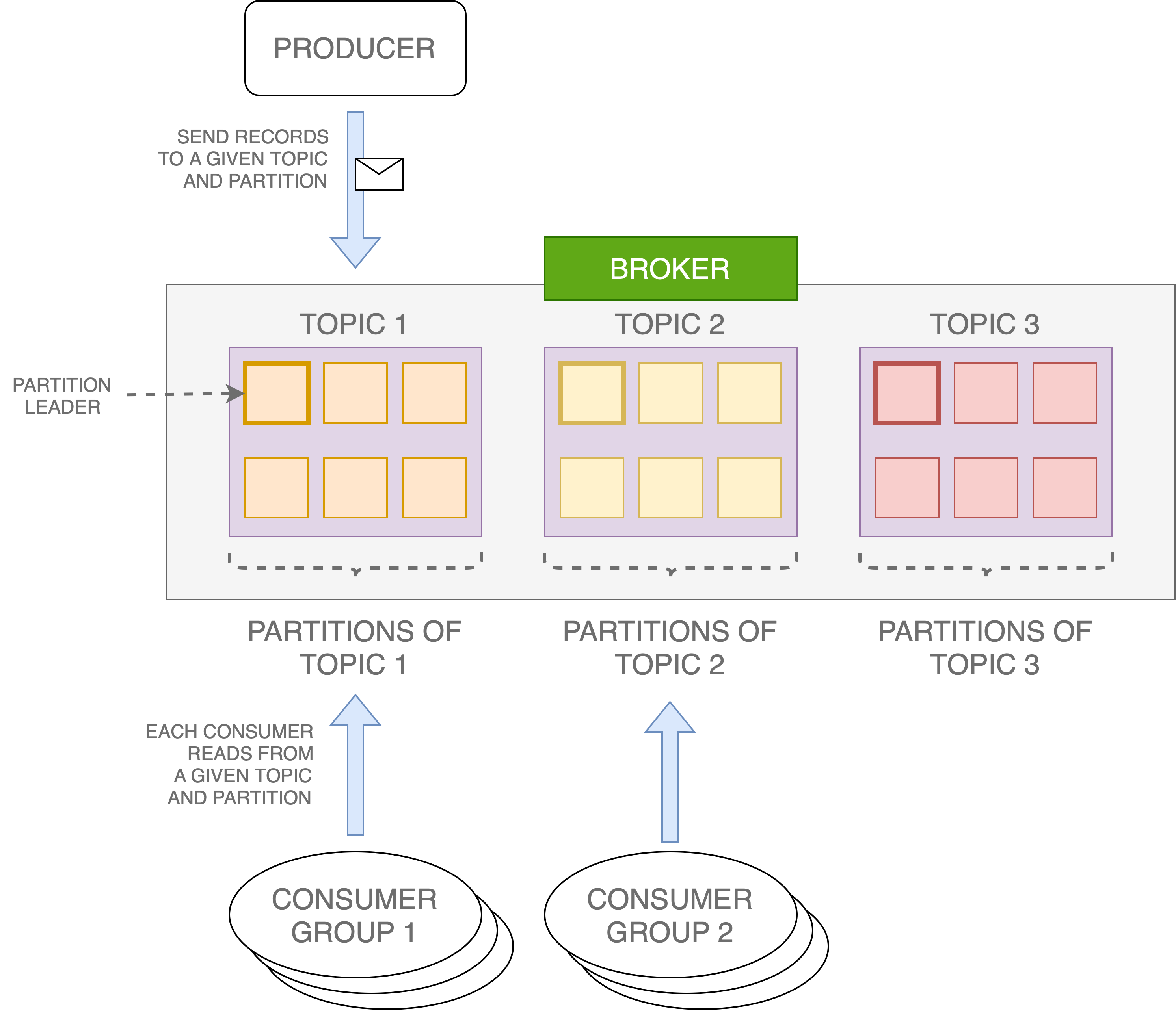
Producers, Consumers and Consumer Groups
In Kafka, each topic is divided into a set of logs known as partitions. Producers write to the tail of these logs and consumers read the logs at their own pace. Kafka scales topic consumption by distributing partitions among a consumer group, which is a set of consumers sharing a common group identifier. Each partition in the topic is assigned to exactly one member in the group, so there will be no two consumers reading from the same partition inside the same group. When all partitions are assigned, there might be some idle consumers.